Today, give a try to Techtonique web app, a tool designed to help you make informed, data-driven decisions using Mathematics, Statistics, Machine Learning, and Data Visualization. Here is a tutorial with audio, video, code, and slides: https://moudiki2.gumroad.com/l/nrhgb. 100 API requests are now (and forever) offered to every user every month, no matter the pricing tier.
Last week I presented ahead, an R package for univariate and multivariate time series
forecasting. In particular, the function dynrmf was introduced for univariate time series,
with examples of Random Forest and Support Vector Machines fitting functions (fitting and predicting through fit_func and predict_func arguments of dynrmf). First things first, here’s how to install R package ahead:
-
1st method: from R-universe
In R console:
options(repos = c( techtonique = 'https://techtonique.r-universe.dev', CRAN = 'https://cloud.r-project.org')) install.packages("ahead") -
2nd method: from Github
In R console:
devtools::install_github("Techtonique/ahead")Or
```R options(repos = c( techtonique = “https://r-packages.techtonique.net”, CRAN = “https://cloud.r-project.org” ))
utils::install.packages(“ahead”) ```
In version 0.2.0 of ahead, Ridge regression is the default fitting function for dynrmf. Let’s see how it works:
library(datasets)
library(ahead)
# We start by a demo of `ahead`'s Ridge regression implementation on random tabular data
set.seed(123)
n <- 100 ; p <- 10
X <- matrix(rnorm(n * p), n, p)
y <- rnorm(n)
# default behavior for ahead::ridge: a sequence of 100 regularization parameters lambdas is provided
fit_obj <- ahead::ridge(X, y)
# plot
par(mfrow=c(3, 2))
# regression coefficients (10) as a function of log(lambda)
matplot(log(fit_obj$lambda), t(fit_obj$coef), type = 'l', main="coefficients \n f(lambda)")
# Generalized Cross Validation (GCV) error as a function of log(lambda)
plot(log(fit_obj$lambda), fit_obj$GCV, type='l', main="GCV error")
# dynrmf with different values of the regularization parameter lambda
# ahead::ridge is provided as default `fit_func`, you can print(head(ahead::dynrmf))
plot(ahead::dynrmf(USAccDeaths, h=20, level=95, fit_params=list(lambda = 0.1)), main="lambda = 0.1")
plot(ahead::dynrmf(USAccDeaths, h=20, level=95, fit_params=list(lambda = 10)), main="lambda = 10")
plot(ahead::dynrmf(USAccDeaths, h=20, level=95, fit_params=list(lambda = 100)), main="lambda = 100")
plot(ahead::dynrmf(USAccDeaths, h=20, level=95, fit_params=list(lambda = 1000)), main="lambda = 1000")
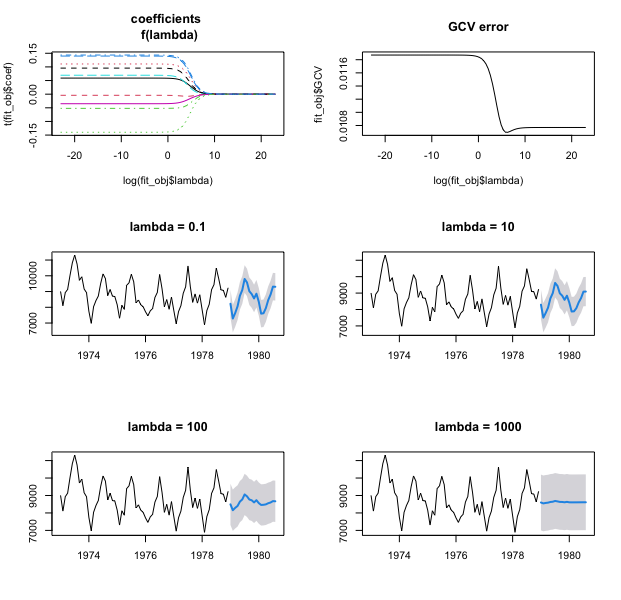
As demonstrated in the previous code snippet, you can try different values of the regularization parameter lambda, and see how ahead’s performance is influenced by each one of your choices.
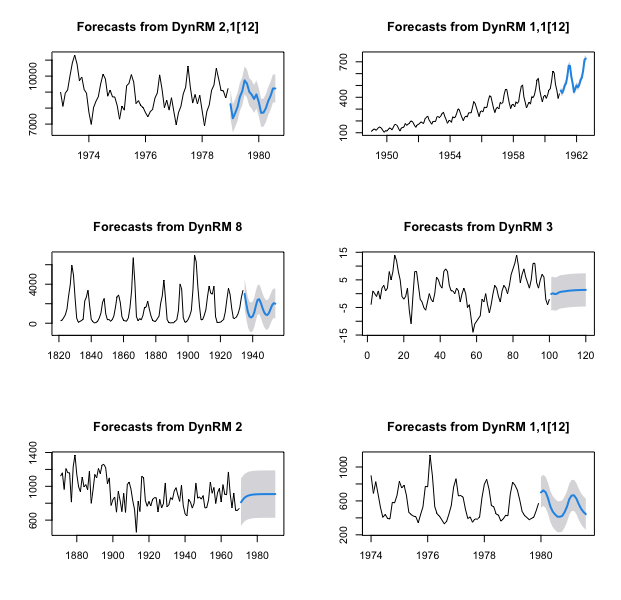
However, if you do not choose a regularization parameter \(\lambda\), the one that minimizes Generalized Cross Validation (GCV) error is automatically (automatically, yes, but not pretending that this will always guarantee the best out-of-sample accuracy) picked internally, on a grid of 100 values. In the examples below of dynrmf, the \(\lambda\) that minimizes Generalized Cross Validation (GCV) error is picked internally :
par(mfrow=c(3, 2))
# nothing else required, default is Ridge regression with minimal GCV lambda
plot(ahead::dynrmf(USAccDeaths, h=20, level=95))
plot(ahead::dynrmf(AirPassengers, h=20, level=95))
plot(ahead::dynrmf(lynx, h=20, level=95))
plot(ahead::dynrmf(diff(WWWusage), h=20, level=95))
plot(ahead::dynrmf(Nile, h=20, level=95))
plot(ahead::dynrmf(fdeaths, h=20, level=95))

Comments powered by Talkyard.